SVM算法介绍
版权声明:本文所有内容都是原创,如有转载请注明出处,谢谢。
引言
在分类和回归的算法中,svm可以说是一个非常经典的算法。尤其是在文本分类,脸部识别以及图片聚类问题上,都有很广泛的应用。随着深度学习的兴起,很多的应用上,SVM渐渐地没落了。不过它在数学上,还是相当的优美,并且也求解过程也很经典,非常值得认真地学习。
Perceptron
算法介绍 说到svm,我们可以先从最简单的perceptron说起。Percetron是最简单的一种分类器。给n个点(X, Y), 假设$X \in R^p, Y \in (0, 1)$,如何得到一个分类器$f(x) = \beta * x + \beta_0$,使得所有被错误分类的点,到分类线的距离最小。对于正确分类的点,我们不关心,以为已经分的对了。而对于错误分类的点,总体来说误差越小越好。这样的话,我们就可以得到下面的式子: $$ D( \beta, \beta_0 ) = - \sum_{i} y_i( \beta x_i + \beta_0 ) $$
根据gradient decent,随机初始化一个$\beta$,然后每次更新$\beta$如下:
$$(\beta, \beta_0 )_{n+1}= ( \beta, \beta_0 )_n + \rho * (y_i x_i, y_i )$$
在扫描几遍数据之后,我们得到一个稳定的$\beta, \beta_0$就可以了。
算法问题
- 算法有无数多个解。每次得到的解都是不一样的。随着初始化,数据的输入,都会发生变化。
- 求解的步数可能很长,gap越小越难收敛
- 如果数据是不可分的,那么算法是不会收敛的。
Best Seperating Hyperplane
在上面求解的过程中,那怎么才是最好的seperating hyperplane呢?SVM提出了一个观点,任何一个类中的点到分类线的距离都是最大的,这个就是最好的。 比如下面这图:
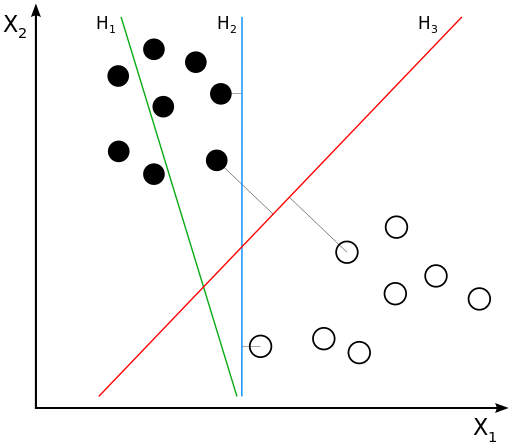
所以从上面,我们可以得到:
$$
\begin{matrix}
\max_{\beta \ \ \beta_0 } M \\
subject \ \ to \ \ \frac{y_i ( \beta x_i + \beta_0 )} {||\beta||} \ge M
\end{matrix}
$$
从上面的式子,我们知道,对于 $ || \beta || $,我们取任何值,它都不会影响点到线的距离,因为我们已经做了归一化了.那么我们就取$ || \beta || = \frac{1}{M} $ 好了, 这样我们可以得到:
$$
\begin{matrix}
\max_{\beta \ \ \beta_0 } \frac{1}{ ||\beta || } \\
subject \ \ to \ \ y_i ( \beta x_i + \beta_0 ) \ge 1
\end{matrix}
$$
稍微转化一下,我们可以得到下面的式子:
$$
\begin{matrix}
\min_{\beta \ \ \beta_0 } \frac{1}{2}{ ||\beta ||^2 } \\
subject \ \ to \ \ y_i ( \beta x_i + \beta_0 ) \ge 1
\end{matrix}
$$
这样的话,我们就可以对上面的式子进行求解了,根据拉格朗日算法,我们可以得到:
$$ L_P = \frac{1}{2}{ ||\beta ||^2 } - \sum_{ i = i}^{n} \alpha_i [ y_i ( \beta x_i + \beta_0 ) - 1 ] $$
对$\beta, \beta_0$,分别求偏导,我们可以得到:
$$
\begin{matrix}
\frac{\partial L_P} {\partial \beta } = \beta - \sum_{i = 1}^{n} \alpha_i y_i x_i = 0 \\
\frac{\partial L_P} {\partial \beta_0 } = \sum_{i=1}^{n} \alpha_i y_i = 0
\end{matrix}
$$
代入原来的式子,我们可以得到一个dual的形式:
$$\begin{matrix}
L_D = \sum_{i = 1}^{n} \alpha_i - \frac{1}{2} \sum_{i= 1}^{n} \sum_{j =1}^{n} \alpha_i \alpha_j y_i y_j x_i^T x_j \\
subject \ \ to \ \ \alpha_i \ge 0 \ and \ \sum_{i=1}^{n} \alpha_i y_i = 0
\end{matrix}$$
从上面的式子,我们可以看到: 1. 如果$\alpha_i >0 $,那么$y_i (\beta x_i + \beta_0) = 1$,那么点就在边界上面 2. 如果$\alpha_i = 0 $,那么点不在边界上面
Non-Seperable Case
上面已经讨论了可分的情况,但是大多数的情况下,数据可没这么友好。很多时候,数据都是不可分的。这样的话,用上面的方法求解,可能就没办法收敛了。那如何处理不可分的情况呢?
定义变量 $\xi = (\xi_1, \xi_2, … ,\xi_n)$. 很自然,我们有两种方法去重新定义上面的约束条件:
$$\begin{array}{c} y_i( x_i^T \beta + \beta_0 ) \ge M - \xi_i \\ y_i( x_i^T \beta + \beta_0 ) \ge M ( 1 - \xi_i ) \\ \forall i, \xi_i \ge 0, \sum_{\xi} \le constant \end{array}$$ 第一个会产生非凸解,而第二个的解是凸的。所以,一般我们都是优化第二个方程。
根据定义,我们可以得到:
$\begin{array}{c} \min_{\beta, \beta_0} \frac{1}{2} ||\beta||^2 \\ subject \ to \ {y_i(x_i^{T}\beta + \beta_0) \ge 1 - \xi_i}, \xi_i \ge 0, \forall i \\ \sum {\xi_i} \le contant . \end{array}$
这个定义和上面的定义区别不大,就是后面的约束稍微改了一下,也比较容易理解。上面的式子也就等价于:
$\begin{array}{c} \min_{\beta, \beta_0} \frac{1}{2} ||\beta||^2 + C \sum {\xi_i} \\ subject \ to \ {y_i(x_i^{T}\beta + \beta_0) \ge 1 - \xi_i}, \xi_i \ge 0, \forall i. \end{array}$
这一步稍微比较难理解一点,以后再说。这样得到拉格朗日方程是:
$$L_P = \frac{1}{2} || \beta ||^2 + C\displaystyle \sum^N_{i=1} \xi_{i}- \displaystyle \sum^N_{i=1} \alpha_i [y_i( x^T_i \beta + \beta_0 ) - (1 - \xi_i) ] - \displaystyle \sum^N_{i=1} \mu_i \xi_i$$
对方程中的每个变量求偏导,我们可以得到:
$$\begin{array}{c} \beta = \displaystyle \sum^N_{i=1} \alpha_i y_i x^T_i \\ 0 = \displaystyle \sum^N_{i=1} \alpha_i y_i \\ \alpha_i = C - \mu_i \end{array}$$
代入Prime中,我们可以得到dual:
$$ \begin{array}{c} L_D = \displaystyle \sum^N_{i=1} \alpha_i - \displaystyle \sum^N_{i=1} \sum^N_{k=1} \alpha_i \alpha_k y_i y_k x^T_i x_k \\ subject \ to \ {\displaystyle \sum^N_{i=1} \alpha_i y_i = 0 \ and \ \alpha_i \ge 0} \end{array} $$
另外,方程在满足TTK conditions的时候,Prime和Dual相等,这也就是我们要求的解。于是有:
$$\begin{array} \ \alpha_i [y_i (x_i^T \beta + \beta_0) - (1 -\xi_i) ] = 0, \forall i \\ \mu_i \xi_i = 0 \\ y_i (x_i^T \beta + \beta_0) - (1 -\xi_i) \ge 0, \forall i \end{array}$$
如何求解
Interior Point Method 这个是优化中最常用的方法。不过我不是很熟悉。不做过多的介绍。
SMO 这个是微软研究出来的算法。SMO也比较简单,比较容易理解。根据定义:$\sum^N_{i=1} \alpha_i y_i = 0$。因此,如果每一次,我们固定一个$\alpha_i$,优化其中一个$\alpha_j$,其他$\alpha_k$都看成常量,这样我们就可以优化$\alpha_j$了。具体的算法可以参考SMO的论文。
Hinge Loss 不论是IPM还是SMO似乎都和平常的优化不太一样,有没有一种算法是基于Gradient Decsent的呢?有的,看下面的优化问题:
$$\displaystyle \min_{\beta, \beta_0} \displaystyle \sum_{i = 1}^N [ 1 - yf(x_i)]_{+} + \frac{\lambda}{2}|| \beta||^2$$
这个优化问题和上面的SVM是一样的。一样的?真的假的?可以证明。而上面的问题, 对我们来说,就比较简单了。直接使用求导,使用LBFGS求解就可以了:
$$\begin{array}{c} \min_{\beta, \beta_0} \frac{1}{2} ||\beta||^2 + C \sum {\xi_i}\\ subject \ to \ {y_i(x_i^{T}\beta + \beta_0) \ge 1 - \xi_i}, \xi_i \ge 0, \forall i. \end{array}$$
证明:很简单的证明,只要稍微整理一下约束条件就可以了。