BloomFilter算法介绍
版权声明:本文所有内容都是原创,如有转载请注明出处,谢谢。
算法引言
问题一:Query 去除 在处理文字链相关广告的时候,遇到这样一个问题。用户很多的搜索,都是检索不到广告的。对于这一类的用户搜索,基本上来说,是没什么价值的。这样的数据也就可以丢弃了。但是,想确定一个搜索有没有价值,我们要匹配所有的广告,接近千万条。而用户的搜索更是上亿,每一个用户搜索都进行一次匹配。这样的匹配,估计现在多少的机器也搞不定。
问题二:URL是否被爬过 这与另外一个问题类似。假设我们在做一个爬虫,有1000亿的url地址,我们想确定一下当前的url有没有被爬过。最简单的想法是,我们直接用一个hash set。但是100亿条数据,也就是10G,每条数据hash一次8个byte,但是hashset的利用效率也就是50%,那也就是需要160GB的内存。现在有机器能存下这么多的内存,估计用起来也是很吃力吧。
算法介绍
Bloom filter 的想法很简单。每个Bloom Filter有两个参数:
- 一个是K,表示有多少个hash function。
- 另外一个是m,表示bloom filter有多少个bit。
Bloom filter的过程很简单,就只有hash和位运算。大致为下面几步:
- 使用k个hash 函数进行hash
- hash以后再对m取余,得到在filter的位置
- 最后对相应的位置置1。
这个是处理输入的过程。判断一个输入是不是在bloom filter中,则进行类似的操作:
- 使用k个hash函数进行hash
- hash以后再对m取余,得到在filter的位置
- 看所有的位置是不是都是1,如果是返回true,否则返回false
图解如下:
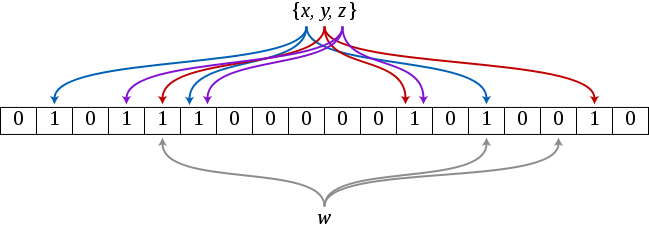
K 和 m的取值
在使用bloom filter的时候,最关键的是设置这两个参数。一般来说,false postive的概率小于0.01就可以了。K一般选择3或者4,而m/n一般选择10左右。所以上面,对于url的处理。我们需要100Gb也就是12GB的内存,或者稍微大一点16GB绝对够了。 具体可以参考曹培教授提供的概率分布
一些想法
Bloom Filter作为可以加载到内存使用的filter,在mapreduce中或者其他需要加载到内存的应用中,都很好用,可以对数据进行集中式处理。
参考资料
吴军 数学之美